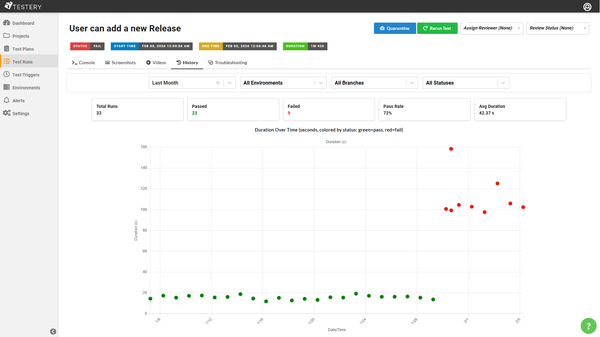
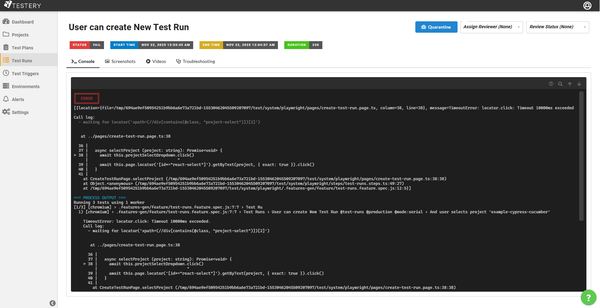
Leading causes of Flaky tests

What is a Flaky Test?
A flaky test is an automated test that validates inconsistent behavior, generating distinct results when implemented multiple times on similar functionality. Such tests are known for their unpredictability, as they can fail or pass intermittently without any alterations to the code or the application under test.
The unreliability of these tests can significantly disrupt the complete test process, resulting in wasted effort, time and decreasing trust in the consistency of the test results. Besides, these tests can be a source of frustration for software developers as their failures don’t always signify the existence of an actual bug.
Flakiness Matters

- Flakiness can mask real bugs
- Flakiness is usually evidence of other issues.
- Flakiness ERODES TRUST (first in the tests, later in the team)
Myths About Flaky Tests
- “Selenium is Flaky”
- “UI Tests are Slow and Unreliable”
- “UI Tests are Flaky”
- “Switching to another tool will fix our flaky tests.”
A New Tool Won’t Save You

- It’s easier to blame our tools than it is to accept responsibility.
- Why do we blame Selenium for flaky tests but not blame React for slow or buggy web applications?
- There are companies with fast, reliable Selenium tests.
- There are companies with flaky Cypress tests.
Why are tests flaky?
-
SUT Not Ready for Testing
This happens if the system-under-test (SUT) isn’t ready to be tested. And it happens more than you would think!
Is the system fully up-and-running? Is it running the new version of the code? Have any database migrations completed? Has all of the test data setup completed? -
Bad Selectors
Selectors that rely on the position of elements or HTML structure will break as the application changes. It’s best to use ids when available, data tags, or unique class names. Well crafted code will often construct selectors using page objects and components.
My favorite approach is to use accessibility tags, since web tests have a lot in common with screen readers. -
“Temporal” Defects
Defects that don’t happen every time are temporal defects. Examples include time zone related issues, date formatting issues, sequential issues, ….
Example: Tests Pass on Rerun Every Morning -
Flaky SUT Infrastructure
Sometimes tests are flaky because the infrastructure for the system under test is flaky.
Example: Misconfigured Load Balancer -
Flaky Test Harness / Runners
Your test harness (i.e. the code that wraps the tests) can also introduce a source of flakiness.
Example: Parallel Tests and Ports -
Network Issues
It’s important to understand how the frameworks you use communicate. If you are running multiple tests on a single device, that device can easily be network IO bound, producing less reliable communication when trying to scale tests!
Example: Hardware-based Load Balancer and Tests -
Test Dependencies
When end-to-end tests run in parallel on the same environment, great care must be taken to make sure they don’t interfere with each other.
➡️ Look for tests that affect user/account settings.
➡️ The failing test isn’t always the problem.
➡️ Provide unique context for each test.
➡️ View test timeline for clusters of red. -
Poor Test Data Management
Sometimes our tests make assumptions about the test data. When the data changes, this can lead to sporadic test failures.
It used to be common to copy production data down into test environments for testing (not done much anymore due to data privacy). When the production data changed, the tests would fail. And are you resetting all of your data before test runs?
Make sure your tests are setting up their data and cleaning up after themselves, even when they fail. -
Sharing Test Environments w/ Humans
Variation is the enemy of reliable, repeatable processes and you want your testing to be reliable and repeatable. Humans are a source of variation. Humans do things like: delete test data, update global configuration settings, create load on the system, delete test accounts, create data... While well crafted tests can defend themselves against humans, your best approach is often to have a dedicated environment for automation whenever possible. -
Code & Test Versions Don’t Match
If you have one version of the tests but are testing five different versions of the code, you should expect test failures.
Make sure the SUT has been fully updated. You don’t want to test the wrong version.
This can be less obvious than you think! (e.g. 3 out of 5 nodes updated to the new version). -
Improper Use of Waits in Tests
Your tests should not rely on arbitrary time delays. This will result in tests that fail when run on infrastructure that’s slower than your dev machine (or perhaps faster!) -
Test Runner Load / Performance
Just like any machine, the machine your tests are running on can become CPU, IO, or memory constrained.
When this occurs, you may start getting unreliable results, usually but not always due to timeouts.
To mitigate this, be sure you are monitoring your test infrastructure with the same diligence you would apply to production. -
SUT Load / Performance
The system-under-test (SUT) may experience CPU, IO, and memory constraints as well. While it’s great that your tests are catching this, it’s better to separate functional testing from load/performance testing. -
Misunderstanding/Handling Exceptions
“stale element” – You saved the found element but the DOM has changed. For most purposes, find element every time you need it.“element not clickable at point” – You may need to scroll the element into view, make sure it’s visible / enabled, etc.
“other element would receive the click” – Happens if there are CSS issues with the site or things like transparent overlays. You can have cleaner CSS or fall back to using JS to click the element.
You got an exception. Did you release resources and clean up after yourself?
-
Not Running Tests Before the Test Run

What to do about flaky tests?
- Productionize” Your Testing
Relax. Take a deep breath. Now imagine your tests not as a QA system, but instead as a production system whose job is to test QA environments. What would you do differently?
Would you start doing things like writing better quality code? Testing your test code? Scaling? Monitoring? Logging? Alerting? What else? - Run More Tests Before Merging
This forces you to “build integrity in”.
You can leverage cloud-based providers to run tests at higher levels of parallelism. - Review Tests for Independence
Make sure tests are setting up and tearing down their test data appropriately (even if they fail).
Have tests run in an independent context if possible (e.g. separate accounts, as separate users, working with separate business objects like invoices, etc.)
Keep an eye out for anything that causes “global” changes to the system (e.g. configurations, user/account settings, etc.) - Join Your Test and SUT Logs
Improving your logs and being able to join system logs with test logs gives you a better view of what steps resulted in a failing test.
Need help getting control of your flaky tests? Contact the team at Testery for a free consultation.